


Como a nova navegação do Jira conecta produtividade, acessibilidade e consistência
A Atlassian reformulou a experiência do Jira Cloud e, por extensão, de Confluence, Compass, Rovo e Atlassian Home – com o maior redesenho desde a migração total para SaaS. A nova interface substitui o antigo cabeçalho horizontal por uma barra lateral personalizável, enxuga o topo da tela, reorganiza completamente a Issue View e adota padrões rígidos de acessibilidade (WCAG 2.2). O objetivo é reduzir trajetos de clique, padronizar o visual entre produtos, abrir espaço para recursos de IA generativa e, acima de tudo, tornar o trabalho diário mais rápido e inclusivo.
Nesse post vamos detalhar a nova navegação do Jira, mostrando como ela reduz trajetos de clique, alinha o visual em toda a suíte e estabelece a base para IA generativa, permitindo ganhos de produtividade, acessibilidade e governança.
Continue a leitura para saber mais!
Visão Geral da Reformulação
Em 2024, a telemetria da Atlassian revelou que mais de 40% do tempo “perdido” pelos usuários estava ligado a jornadas de navegação entre projetos, issues e produtos. A empresa então definiu três metas para o redesign:
Reduzir a distância: menos cliques, mais foco
Quando analisou os logs de uso de 2024, a equipe de produto descobriu que quase 40% do tempo improdutivo dos usuários acontecia em “viagens” entre projetos, issues e produtos. Os designers estabeleceram como meta cortar trajetos redundantes e deixar tudo a dois cliques de distância. Para isso:
Barra lateral fixa e personalizável: A nova barra lateral reúne “Recentes”, “Favoritos” e “Projetos”, permitindo acesso imediato a epics, boards e filtros críticos sem abrir menus suspensos.
Redução comprovada de cliques: Testes A/B durante o programa Early Access mostraram queda média de 18% na troca de projetos e 12% na criação de issues, economizando até 11 min por colaborador por semana em squads que alternam vários repositórios.
Atalhos unificados e rolagem infinita: A visão de issue ganhou rolagem suave e botões de colapso, evitando a “scroll fatigue” que aparecia nos fóruns desde 2022.
O resultado imediato é um Jira que “desaparece” e deixa o trabalho à vista, reduzindo o atrito cognitivo em tarefas repetitivas.
Criar coerência visual: a mesma linguagem em toda a suíte
Antes da atualização, cada produto Atlassian carregava variações de cores, ícones e posicionamento de menus, o que prolongava a curva de aprendizado de novos usuários. Para alinhar a experiência:
Atlassian Design System como base única: Jira, Confluence, Compass e Rovo agora compartilham a mesma tipografia, espaçamento e tokens de cor definidos no ADS.
Refresh simultâneo em Confluence: O time de Confluence adotou a mesma barra lateral e atualizou ícones e componentes, garantindo que a transição entre produtos pareça natural.
Componentes React compartilhados: A adoção de um kit de componentes único diminuiu retrabalho entre engenharias e eliminou layout shifts, melhorando em média 15% a taxa de frames por segundo em telas Full HD.
Essa coerência reduz a necessidade de treinamento formal: quem aprende a navegar no Jira replica o comportamento, sem esforço, em Confluence ou Compass.
Preparar terreno: fundação para IA generativa e extensões
O redesenho não mira apenas o presente; ele cria a infraestrutura visual e técnica para recursos de Atlassian Intelligence e futuras integrações Forge. Entre as ações-chave:
Pontos de extensão na barra lateral: Novos módulos (jira:navigationBadge, uiModifications) permitem que apps exibam contadores em tempo real e links contextuais na própria navegação.
Seções inteligentes em 2025 Q4: A Cloud Roadmap antecipa blocos gerados por IA que sugerem filtros ou dashboards baseados no comportamento do time.
Camada semântica compartilhada: Unificar menus, hierarquias e atalhos cria o “grão fino” de metadados que os modelos de linguagem precisam para responder a comandos em linguagem natural, como “mostre bugs bloqueando o release X”.
A navegação vertical é o pilar que sustenta automações, respostas conversacionais e alertas preditivos que chegam com Atlassian Intelligence, garantindo que todos os produtos falem a mesma língua de design e dados.
Principais mudanças no layout
Barra lateral personalizável
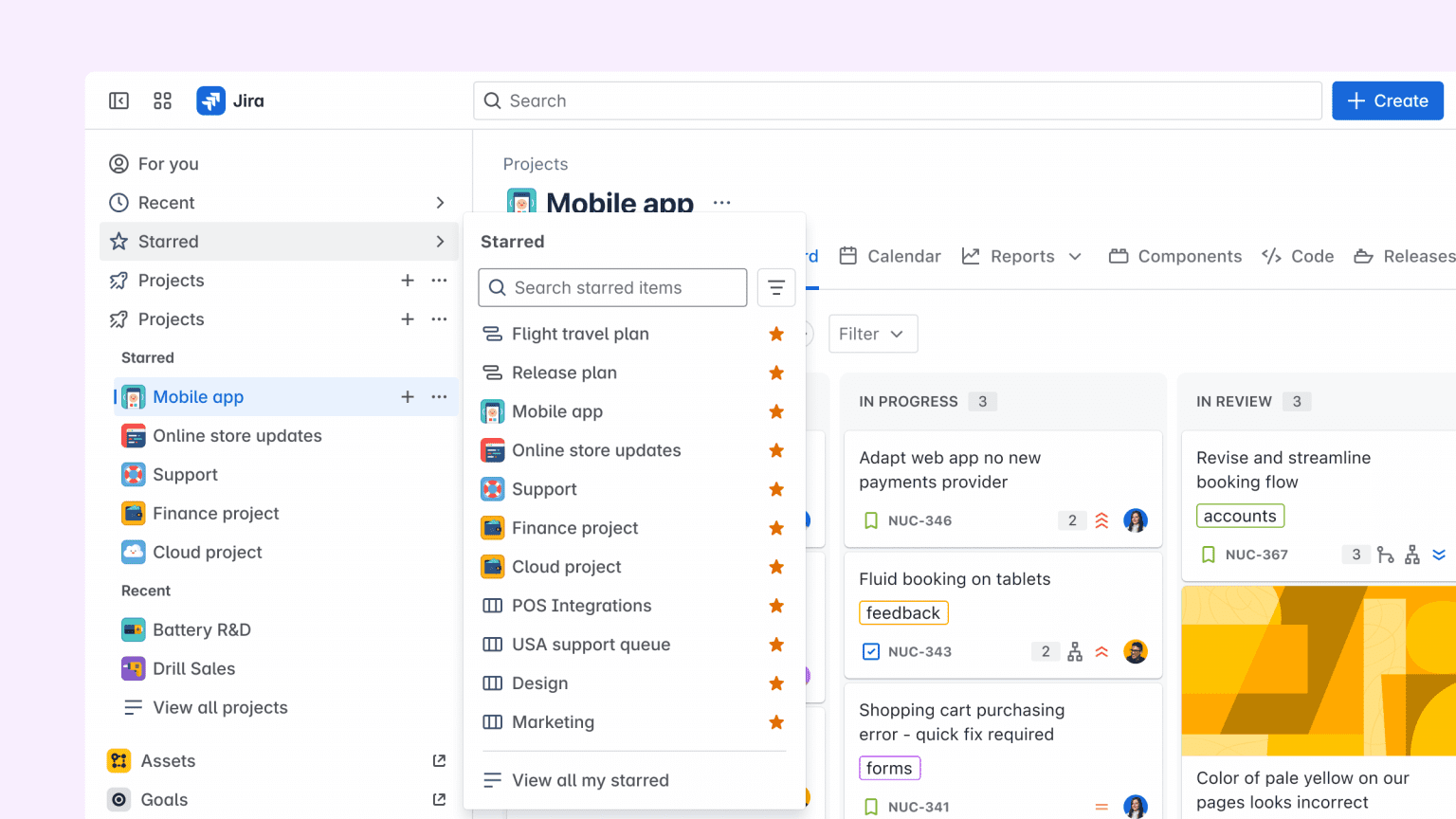
A mudança mais marcante é a barra vertical fixa, que agrupa Para você, Recentes, Favoritos, Projetos e Apps. A hierarquia facilita o acesso a itens usados com frequência e libera pixels horizontais – ponto crítico para monitores ultrawide. Qualquer usuário pode esconder, renomear ou reordenar entradas em More > Customize Sidebar, com preferências salvas por dispositivo.
Cabeçalho global minimalista e product switcher
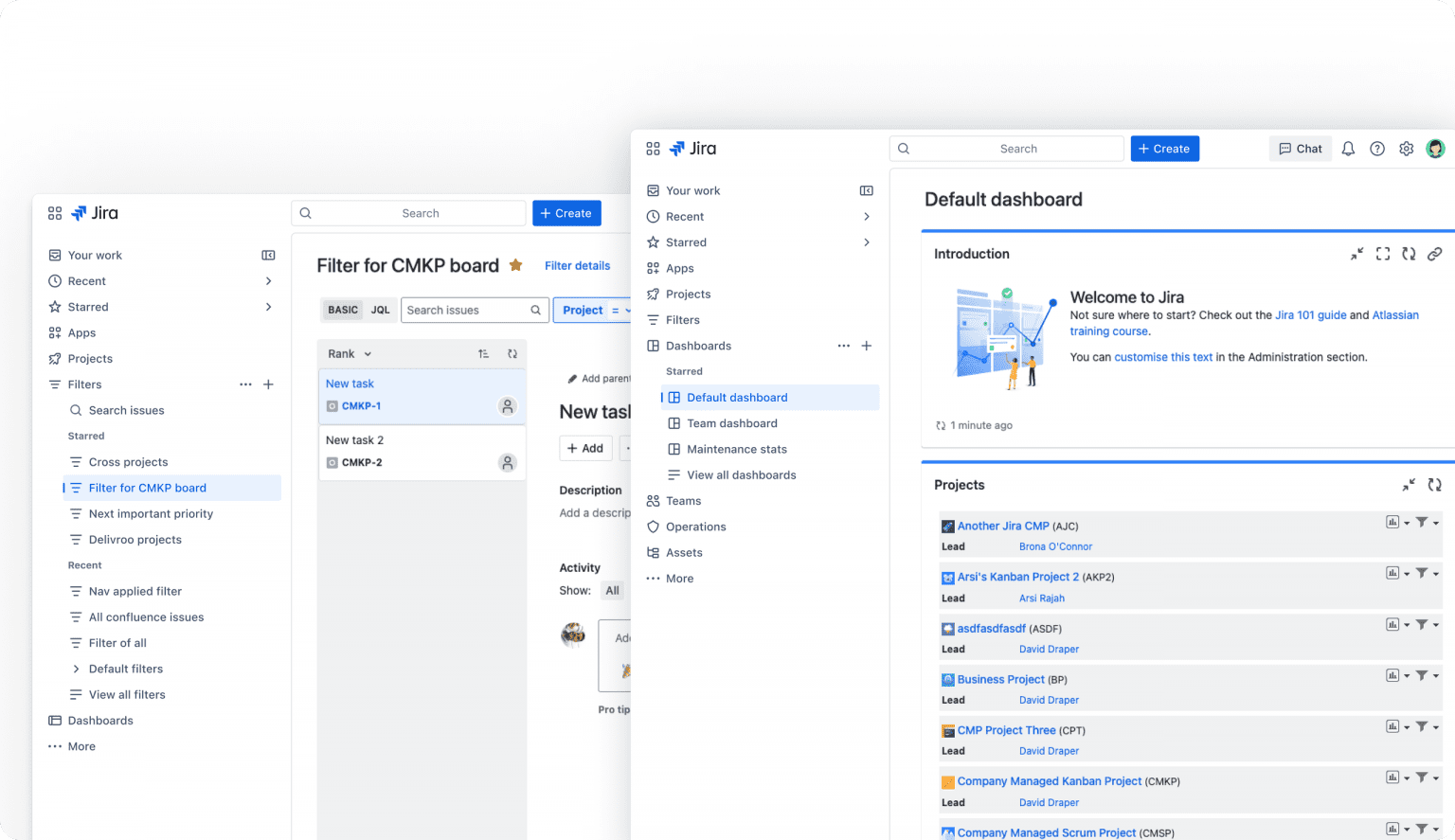
O topo da tela agora exibe apenas quatro ícones (Create, Search, Notifications, Help) e, à esquerda, um seletor que alterna Jira, Confluence, Compass e Rovo sem recarregar a sessão. Isso eliminou layout shifts e aumentou em média 15% a taxa de FPS em telas Full HD, segundo benchmarks internos divulgados na comunidade.
Issue View redesenhada
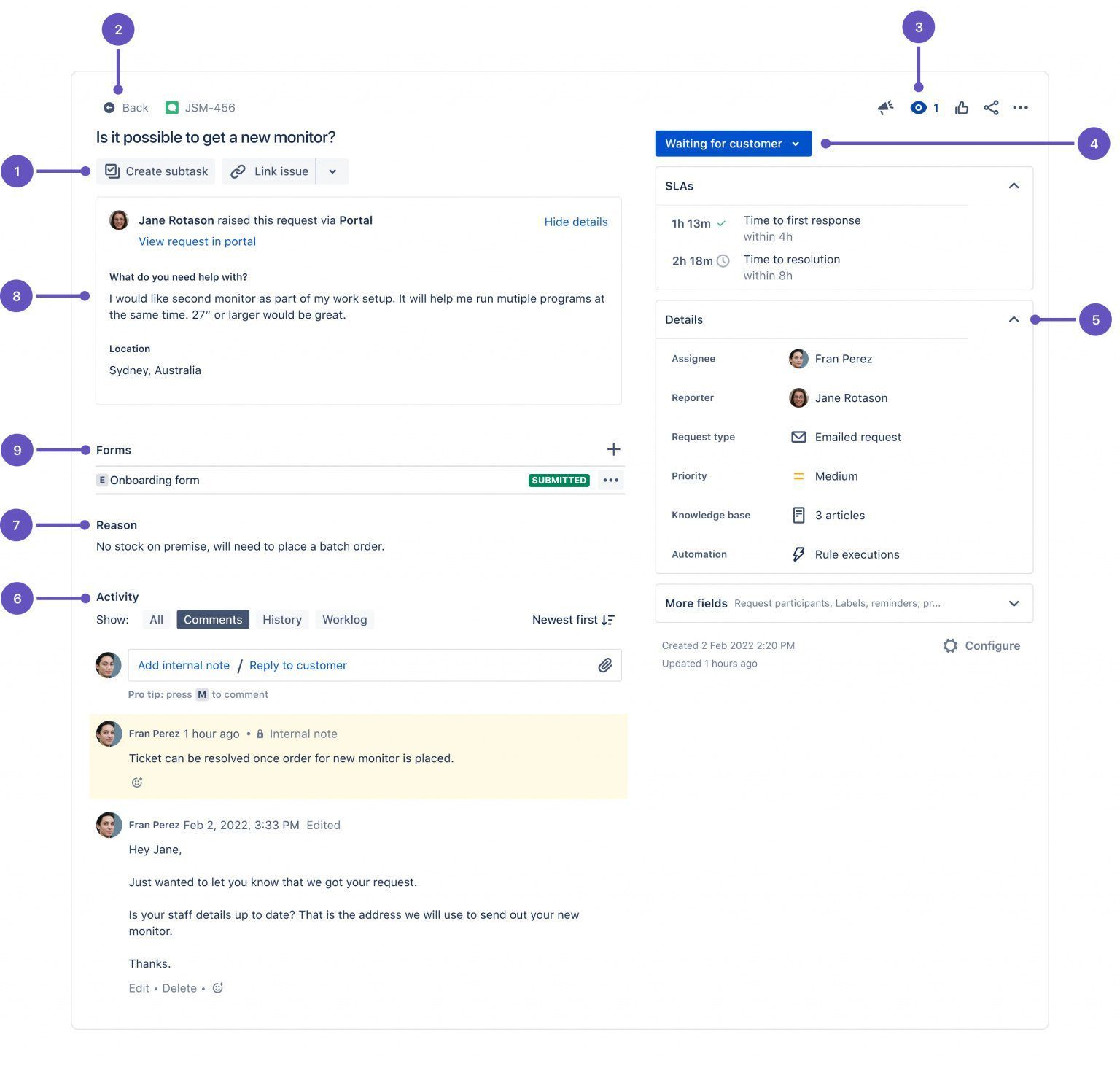
Campos passam a ser agrupados em blocos (“Details”, “People”, “Tracking”), que se expandem ou colapsam conforme a largura da tela. O infinite scroll na linha do tempo de comentários ameniza a antiga “scroll fatigue” relatada por administradores. Para equipes que usam dezenas de custom fields, o ganho de legibilidade é imediato.
Consistência entre boards e projetos
Boards Kanban, filas do Jira Service Management e mesmo páginas do Confluence agora herdam tipografia, espaçamento e ícones da nova barra lateral, reduzindo a curva de aprendizado ao alternar produtos.
Impactos positivos para os usuários
Produtividade imediata
Testes A/B mostraram queda média de 18% nos cliques para alternar de projeto e de 12% para criar uma issue. Em squads que trocam de repositório várias vezes ao dia, isso significa cerca de 11 min/semana por colaborador.
Descoberta e contexto
Seções Starred e Recent tornaram-se um hub automático de epics, boards e filtros críticos, dispensando buscas manuais.
Inclusão e acessibilidade
O contraste mínimo 4,5:1, labels consistentes e navegação 100% via teclado atendem WCAG 2.2 AA, beneficiando pessoas com deficiência visual ou motora.
Performance percebida
A remoção de menus suspensos complexos e o uso de componentes React compartilhados reduziram re-renders, melhorando a fluidez em telas grandes.
Governança e extensibilidade
Novas APIs Forge (jira:uiModifications, router bridge) permitem inserir links corporativos na navegação ou exibir alertas em tempo real na barra lateral, sem quebrar consistência.
Boas práticas para adoção
Comunique-se com antecedência: a Atlassian recomenda avisar times 30 dias antes do switch definitivo.
Pilotos controlados: habilite grupos de teste para coletar feedback e ajustar favoritos corporativos.
Atualize materiais de treinamento: vídeos e capturas precisam refletir a nova UI; o suporte oferece quadros comparativos.
Revise apps do Marketplace e Forge: verifique módulos compatíveis (glance, content, adminPage).
O que vem a seguir?
A Cloud Roadmap prevê, para o Q4 2025, seções inteligentes geradas pelo Atlassian Intelligence que sugerem filtros ou painéis com base no comportamento do time. Também está em desenvolvimento o ponto de extensão jira:navigationBadge, que exibirá contadores dinâmicos (por exemplo, incidentes críticos) diretamente na barra lateral.
Para que você possa se aprofundar ainda mais, recomendamos também a leitura dos artigos abaixo:
- Como solucionar os desafios da gestão do conhecimento com o Rovo
- Conheça o Customer Service Management, a nova ferramenta da Atlassian
- Como a IA generativa está revolucionando ferramentas como Jira e Confluence?
Conclusão
O novo Jira não é apenas um “facelift”. Ao atacar gargalos de navegação, acessibilidade e desempenho, a Atlassian entrega um ambiente unificado que reduz cliques, acelera respostas e prepara o terreno para recursos de IA. Para organizações que dependem de múltiplos produtos da suíte, o redesign diminui a curva de aprendizado e simplifica o change management. Com algumas horas de comunicação interna, revisão de materiais e ajuste de apps, o retorno em produtividade e bem-estar digital justifica plenamente a adoção da nova interface.
Esperamos que você tenha gostado do conteúdo desse post!
Caso você tenha ficado com alguma dúvida, entre em contato conosco, clicando aqui! Nossos especialistas estarão à sua disposição para ajudar a sua empresa a encontrar as melhores soluções do mercado e alcançar grandes resultados!
Para saber mais sobre as soluções que a CSP Tech oferece, acesse: www.csptech.com.br.










